Can AI-written code survive code review?
What SWE-Bench-style benchmarks asked was one thing: “Does it pass the tests?” That was all. Feature works, you score; it doesn’t, you get zero. But you know that feeling when an AI agent’s code lands in your queue as a PR? “Well, it runs… but am I really comfortable merging this?” No benchmark had ever measured that gap.
FrontierCode, which Cognition released in June 2026, asks a different question: “Would the actual maintainer merge this PR?”
How it was built
More than 20 maintainers from 36 open-source repositories designed the tasks themselves – projects with tens of thousands of stars, like Celery, Budibase, Mattermost, and uppy. Each task took over 40 hours to build, and every one was manually verified by Cognition researchers.
The prompt length stands out too. They kept it to about a third of SWE-Bench Pro’s – much closer to how real work happens. No team lead writes a novel in your ticket. The instruction is as terse as “wrap this warning log in a new function and apply it across the codebase,” and the agent figures out the rest from context.
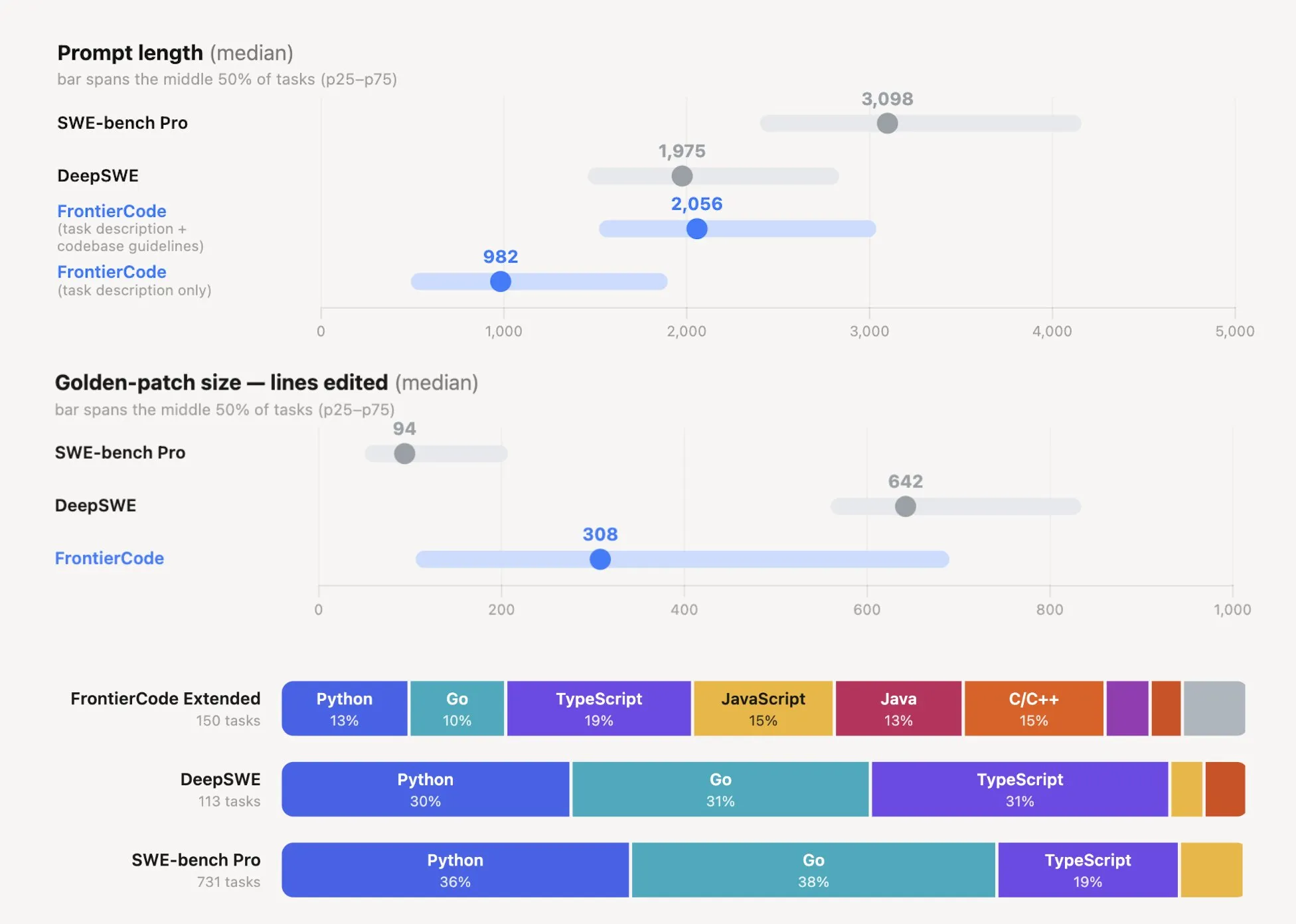
With only the task description given, the median prompt is 982 tokens. Compare that to SWE-Bench Pro’s 3,098 – less than a third. The golden patches run the other way: a median of 308 lines versus SWE-Bench Pro’s 94. Short instructions, broad changes – a combination much closer to real work. The language mix doesn’t lean on Python either, spreading evenly across TypeScript, JavaScript, Java, and C/C++.
One maintainer’s comment stuck with me: “Other benchmarks grade like CI. FrontierCode grades like a tech lead.”
The six grading axes
FrontierCode evaluates along six dimensions.
- Functional correctness: does it actually solve the problem
- Regression safety: does it avoid breaking existing code
- Mechanical polish: passing builds, linters, style checks
- Test correctness: do the agent-written tests actually catch the problem
- Scope: did it touch only the necessary files, with no gratuitous refactoring
- Code quality: codebase conventions, readability, design patterns
The “scope” criterion resonates most with me. In my experience, the most frequent pattern in AI agent code is “wait, it touched this file too?” – changing more than was asked, or quietly nudging completely unrelated files. The code runs, but as a reviewer you feel uneasy.
Each criterion is classified as a “blocker” or “non-blocker.” Fail even one blocker and the score is simply zero. The rest are weighted and summed.
The Diamond report card
The benchmark has three tiers: Extended (150 tasks), Main (100), and Diamond (50, the hardest). Looking at the Diamond numbers, frankly, they’re low.
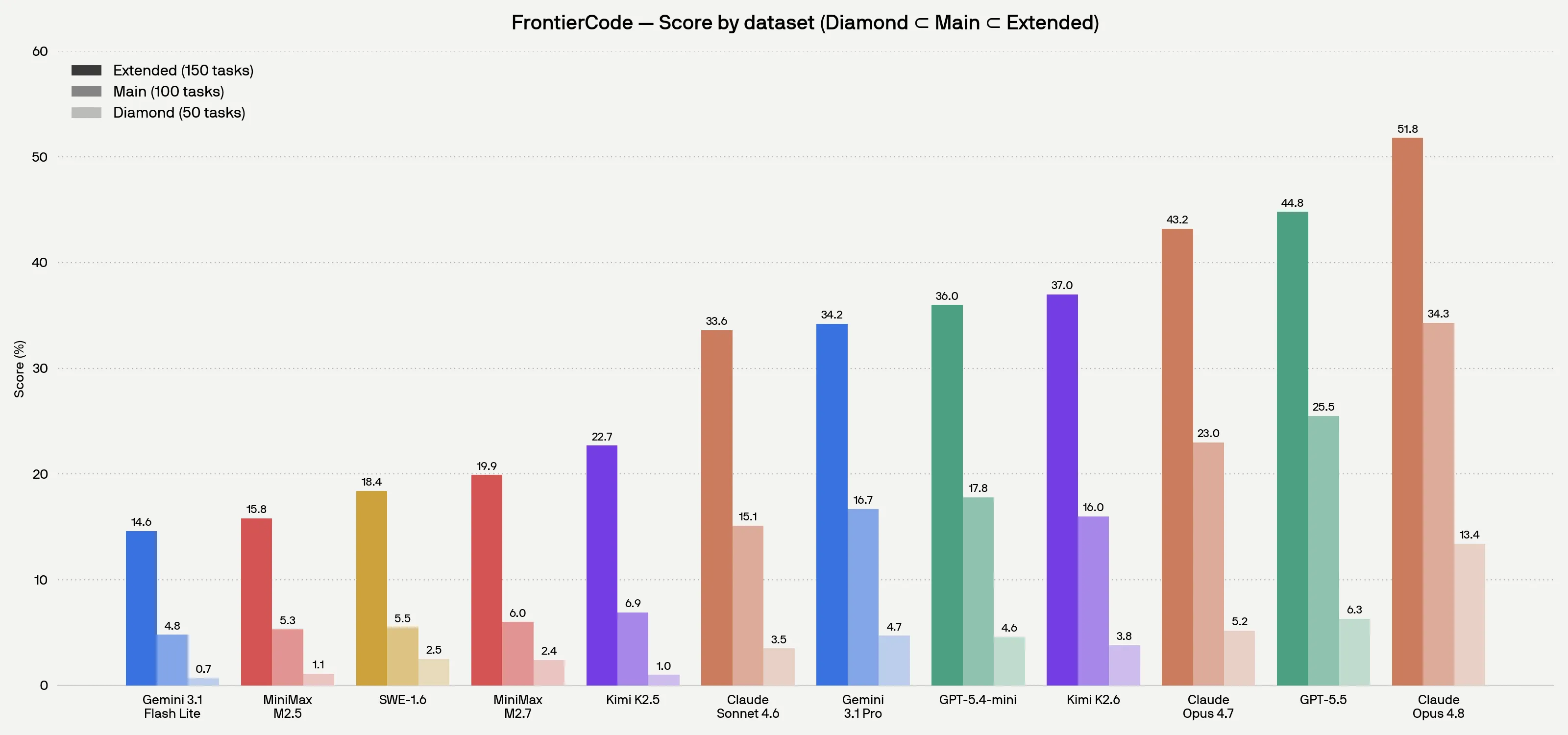
You can see the bars drop off a cliff as the tiers get harder. The same model loses three quarters of its score going from Extended to Diamond.
| Model | Diamond score |
|---|---|
| Claude Opus 4.8 | 13.4% |
| GPT-5.5 | 6.3% |
| Gemini 3.1 Pro | 4.7% |
| Kimi K2.6 (best open-source) | 3.8% |
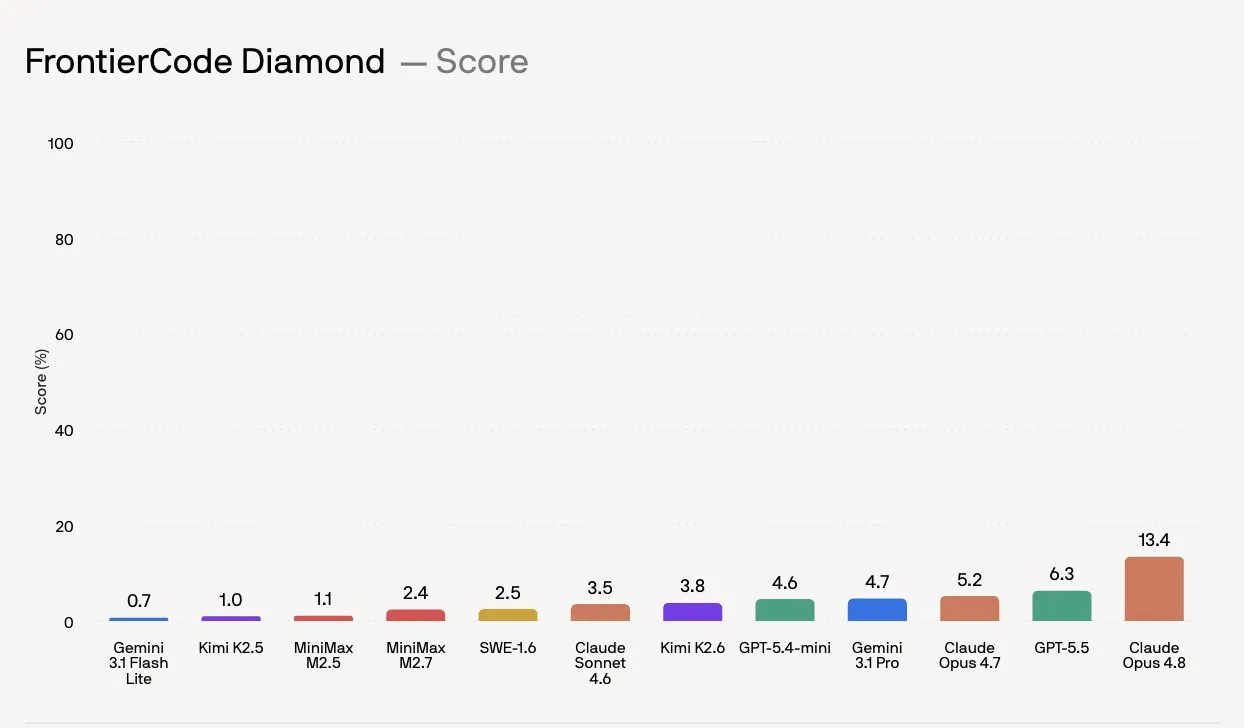
First place, Claude Opus 4.8, sits at 13.4%. Models that were posting 80–90% on SWE-Bench Verified drop into the low double digits once quality criteria enter the picture. Opus 4.8 scores 34.3% on Main and 51.8% on Extended, so the gap widens sharply as difficulty climbs.
GPT-5.5 is second on Diamond at 6.3%, but it consumes up to 4x fewer tokens than Opus 4.8 – a meaningful difference in cost-performance terms.
The C++ logger task: code that runs vs. code that merges
One concrete example the FrontierCode team published captures the benchmark’s character well.
The task: in a C++ project, create a new auto LOG_WARNING() -> std::ostream & function and replace warning logs across the entire codebase. The crux was how multi-line warning messages get handled.
The correct implementation looks like this:
LOG_WARNING() << "You are opting in to remove schema identifiers... \n"
<< "The only legit use case...\n"
<< "non-compliant...\n" << ... ;Claude Opus 4.8 did this:
LOG_WARNING() << "You are opting in to remove schema identifiers...\n";
std::cerr << "The only legit use case...\n";
std::cerr << "non-compliant...\n";The output is identical. For now. But what happens later when LOG_WARNING()’s stream implementation changes? Only the first line goes through the new logger; the rest escape straight to std::cerr. The assumption gets baked into the call site. A human reviewer would catch this detail – but by the “tests pass” standard, there’s nothing wrong.
An honest assessment
I welcome this direction. As more teams wire AI agent code into production, every one of them ends up saying “the tests all pass, but the code quality is…” Someone finally tried to capture that feeling in a number.
The grading reliability shows care too. Running each task 45 times, the false-positive rate – “passed but actually wrong” – comes out to 6.9%. Compare SWE-Bench Pro’s 36% and the difference is stark.
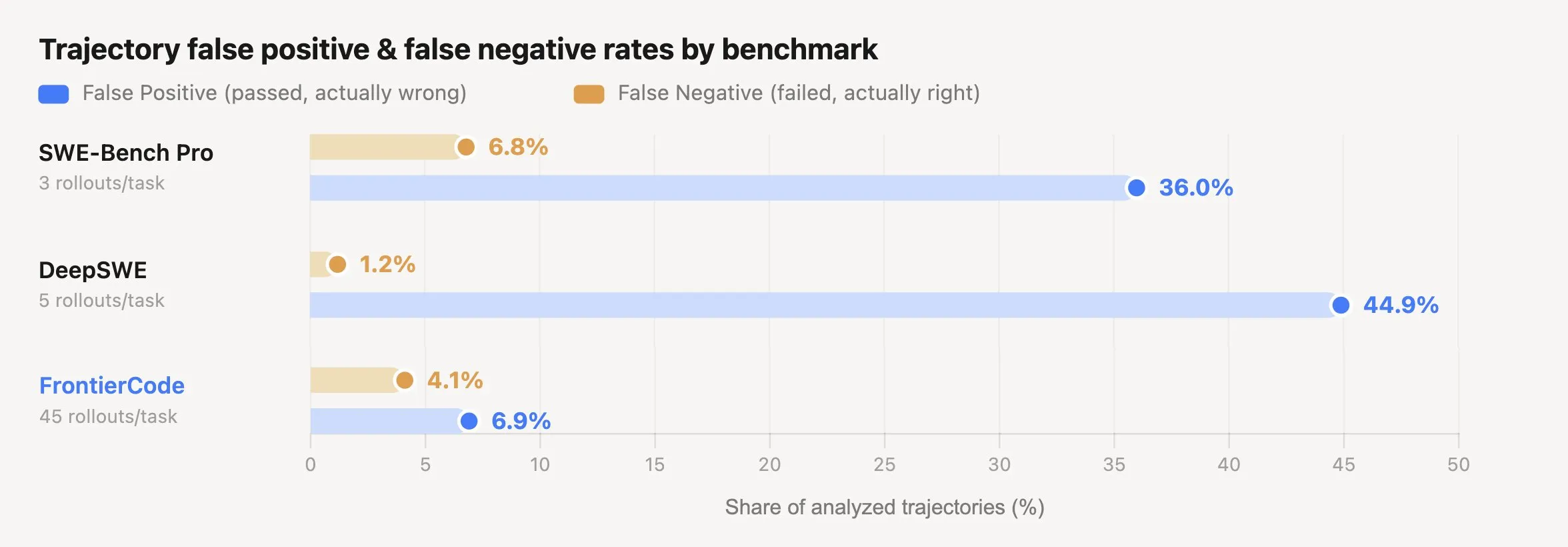
When the pass verdict is loose, scores inflate and the benchmark itself becomes hard to trust. A strict grader puts weight behind the numbers.
There are limits, though.
Part of the code-quality grading is done by an LLM. When the grader is a model, that model’s biases come along. With Claude Opus 4.8 in first place while an LLM handles part of the evaluation, that’s a structural point worth examining.
The task set won’t be published. It’s for contamination prevention, and I get it, but it also means outsiders can’t reproduce or verify the results. There’s also the inherent limit of encoding maintainers’ judgment into subjective rubrics – two maintainers looking at the same PR can disagree.
Still, graduating from “test pass rate” to “mergeability” matters. For any team handing code to AI, that Diamond 13.4% is a number worth remembering coldly: even today’s best model, judged on quality, produces something merge-ready about one time in ten.
Source: Cognition, “FrontierCode”